论文笔记:Event Detection with Trigger-Aware Lattice Neural Network
本文共 793 字,大约阅读时间需要 2 分钟。
作者:崔金满 单位:燕山大学

论文链接:
代码地址:
数据集:ACE 2005 和 KBP 2017 (中文语料)
来源:EMNLP 2019
事件检测包括触发器识别和对事件提及进行分类两个子任务,对于没有分隔符的中文来说主流的方法是基于词汇的模型,即首先对句子进行分词,然后再执行后续任务。
针对问题:
- 触发词不匹配问题:如一个触发器属于一个词的一部分,或者由多个词组成。在下图中,“射”和“杀”两个触发器分别对应两个不同的事件,却在中文分词过程中往往会将其分为一个词“射杀”;
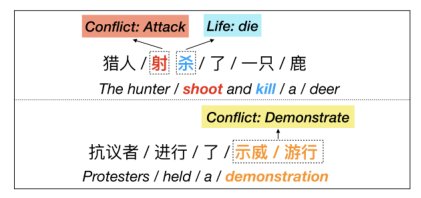
- 一词多义引起的事件分类错误:由于同一个词在不同的语境下,常常会表现不同的含义,所以在事件分类过程中,还会受到触发词一词多义的影响。

创新:
- 提出TLNN模型,同时解决触发词不匹配和一词多义问题;
- 利用外部知识库来获取语义信息。
模型:
本文将事件检测视为序列标注任务,将字符序列输入模型,然后模型将识别每个字符是否为触发器的一部分,并将其进行正确分类。

- 分层表示学习
将文本分为字符级(character level)、单词级(word level)和基于HowNet的语义级(sense level)三个层级进行表示
- 触发词感知特征提取
在抽取触发词特征时,本文在传统LSTM的基础上 ,利用额外的LSTMCell来整合字符、单词的所有语义信息。

获取字符级语义信息为例:
首先通过HoeNet获取字符 的所有语义,然后将第j个语义表示
输入LSTMCell,从而得到cell gate
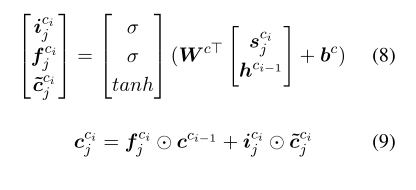
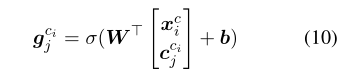
然后,对所有的语义信息进行整合,保存到临时的单元状态

在获取字符级和单词级的临时细胞状态之后,通过一个额外的门对其进行整合,得到隐藏状态向量。
- 序列标注
将每个字符的隐藏向量作为输入,使用CRF进行序列标注
实验
本文在ACE和KBP两个数据集上分别通过与基于字符和基于词的模型进行对比,从整体上看均取得了很好的效果

转载地址:http://bqmgi.baihongyu.com/
你可能感兴趣的文章
javascript设计模式-享元模式(10)
查看>>
javascript设计模式-代理模式(11)
查看>>
Executor相关源码分析
查看>>
react之setState解析
查看>>
elasticsearch7.3版本已经不需要额外安装中文分词插件了
查看>>
【重大好消息】elasticsearch 7.3版本已经可以免费使用x-pack就可以设置账号和密码了,让你的数据不再裸奔
查看>>
解决使用logstash中jdbc导入mysql中的数据到elasticsearch中tinyint类型被转成布尔型的问题的方法
查看>>
elasticsearch7.3版本环境搭建(一)elasticsearch安装和配置
查看>>
SEO基本功:站内优化的一些基本手段
查看>>
centos6系列和7系列如何对外开放80,3306端口号或者其他端口号
查看>>
为什么您宁愿吃生活的苦,也不愿吃学习的苦?为什么你不愿意去学习呢
查看>>
解决elasticsearch7.3版本安装过程中遇到的包括内存不够、线程不够等问题
查看>>
日常项目测试用例检查点(来自一线测试人员的吐血总结)
查看>>
网站建设之域名注册和域名备案
查看>>
解决bootstrap时间输入框总被浏览器记住的记录遮挡住的问题
查看>>
git将一个分支完全覆盖另外一个分支如:dev分支代码完全覆盖某一个开发分支
查看>>
elasticsearch7.3版本环境搭建(二)可视化管理后台kibana的安装和配置
查看>>
elasticsearch7.3版本环境搭建(三)可视化管理后台kibana的汉化(设置中文界面)
查看>>
记录一次DDos攻击实战
查看>>
分享一首小诗--《致程序员》
查看>>